
📃 프로젝트 설명
클라우드 환경에서 웹이나 앱서비스 데이터 수집을 위한 토이 프로젝트이다.
온프레미스에서 Logstash와 kafka를 이용한 수집을 클라우드 환경으로 마이그레이션하는 방법을 습득하는 것이 목표이다.
이 프로젝트의 특징은 RestAPI로 받은 데이터를 다른 AWS 서비스나 Lambda 서비스를 사용하지 않고 Velocity문법으로 데이터를 parsing하여 비용절감 효과를 가진다.
이전 블로그에서 Api-Gateway, Kinesis의 개념을 정리 해보았다.
이전 블로그 링크 : https://foot-data-engineering.tistory.com/4
현 블로그에서는 이를 활용해서 Kinesis를 사용하면 데이터가 S3 또는 RedShift로 전송될 수 있기에 이를 사용해 보려 한다. (+Kinesis를 통해 데이터가 적재되기 전 람다로 데이터 분석도 가능하다. )
하지만, 지금 정리하는 프로젝트 내용에는 좀 더 심플한 데이터 파이프라인에 대한 고안으로 람다를 사용하지 않고 Api-Gateway의 안의 Velocity문법으로 데이터를 처리하고자 한다. 더불어 람다를 사용하여 에러발생시 람다가 4번까지 재작동하여 중복데이터가 생기는 부분이 생기므로 이를 꼭 체크해줘야하는 니즈가 생기는데 이를 해결하는 방안이기도 하다.
활용에 앞서 Kinesis와 kafka의 차이는 무엇일까?
kinesis vs kafka
간단히 정리하자면 Kinesis Streams 는 Kafka Core 와 같고, Kinesis Analytics 는 Kafka Streams 와 같다 . Kinesis 샤드 는 Kafka 파티션 과 같다 .
Kafka는 Kinesis보다 유연하지만 자체 클러스터를 관리해야 하며 계속 유지하려면 전용 DevOps 리소스가 필요하다.
즉, Kinesis는 서비스로 판매되며 계속 유지하기 위해 DevOps 팀이 필요하지 않게된다. 이 말은 Kafka클러스터를 관리하는 비용과 직원에 대한 임금을 고려하여 Kinesis의 사용 비용을 감안하여 판단해야 할 것이다.
자세한 내용은 아래 링크에 참조 되어있다.
Kinesis vs. Kafka
Tweet Kinesis vs. Kafka Kinesis works with streaming data. Stock prices Game data (scores from game) Social
cloudurable.com
구성도는 다음과 같다.

1) Api-Gateway
1-1) api-gateway 중에 사용자의 데이터를 여러 방식 중 REST API를 통해 받기 위해 다음과 같이 생성한다.

1-2) api를 생성하면 그 하위 작업에서 리소스 생성과 메서드 생성이 있는데 리소스는 활용하자면 여러개의 리소스를 만들어서 버전관리를 한다고 생각하면 편하다. 그 리소스들에 따른 하위 작업으로 메서드를 생성하는데 restapi의 메서드들을 작업할 수 있다.

1-3) version1,2의 리소스를 생성했고 그 하위 작업의 POST방식의 메서드를 사용해보고자 한다.

1-4) 더욱 좋게 활용할 수 있는 장점은 각 리소스들의 하위리소스 네임에 "{ }" 사용하여 각 엔드포인트를 다르게 설정하고 각 엔드포인트에 따라 여러 서비스에 대한 데이터를 달리 저장할 수 있다. (자세한 설정은 뒤의 Kinesis 설정에서 다룬다.)

1-5) POST 메서드에 대한 설정으로 지금은 api-gateway를 통해 kinesis로 연결 하기위해 다음과 같이 설정하는데 실행역할으론 api-gateway가 kinesis에 접근가능하도록 iam에서 역할에 정책을 설정해주면 된다.
(1-6부분에 역할 설정) 작업에 대한 내용은 Amazone에서 설정한 부분인데 https://docs.aws.amazon.com/ko_kr/apigateway/latest/developerguide/integrating-api-with-aws-services-kinesis.html docs를 읽어보면 자세히 나와있다.
자습서: API Gateway에서 REST API를 Amazon Kinesis 프록시로 생성 - Amazon API Gateway
클라이언트에 의해 호출된 메서드에 대한 HTTP 동사는 백엔드에서 요구하는 통합에 대한 HTTP 동사와 다를 수 있습니다. 여기에서는 [GET]을 선택했는데, 목록 스트림이 본질적으로 읽기(READ) 작업
docs.aws.amazon.com

1-6) 역할설정에서 정책으로 AmazoneKinesisFullAccess정책을 할당하고 위의 ARN주소를 적용하면 된다. 사실 이부분은 현업에서 AWS의 사용자가 관리자로부터 권한을 받아 사용하는 부분이며 본인은 테스트용이기에 직접 설정한다. CloudWatch 정책은 Kinesis의 로그를 확인할 수 있게 default로 설정되어있다.

1-7) 위 설정을 마치고 메서드를 보면 다음과 같이 워크플로우가 형성된다.

1-8) 통합요청 설정에서 Velocity 문법으로 데이터를 처리한다.
Content-Type은 RestAPI의 경우 보통 JSON타입으로 요청하고, 요청을 받는다. 그래서 당연히 application/json 타입으로 Content-Type 사용한다고 생각을 하는 경우가 많은데, 자료를 찾다보니 그렇지 않다는걸 알게되었다.
html form 태그를 사용하여 post 방식으로 요청하거나, jQuery의 ajax 등의 요청을 할때 default Content-Type은 'application/json'이 아니라 'application/x-www-form-urlencoded'다.
그러므로 두 방식을 둘다 처리해 줄수 있게 두가지 매핑 템플릿을 설정한다. 매핑 템플릿은 앞서 말한것과 같이 velocity 문법이며 각 들어오는 방식에 대한 parser를 작성해준다.
문법이 매우 생소하기에 참고자료는 다음과 같다.
Amazon API Gateway 매핑 템플릿과 Amazon SageMaker를 통한 기계 학습 기반 REST API 생성하기 | Amazon Web Servic
AWS 고객들은 완전 관리형 기계 학습 서비스인 Amazon SageMaker를 사용하여 기계 학습 모델을 구축, 교육 및 배포 할 수 있습니다. 이를 통해 개인화 된 제품 추천을 하거나, 사용자에 따른 선호 사항
aws.amazon.com
API Gateway mapping template and access logging variable reference - Amazon API Gateway
This function will turn any regular single quotes (') into escaped ones (\'). However, the escaped single quotes are not valid in JSON. Thus, when the output from this function is used in a JSON property, you must turn any escaped single quotes (\') back t
docs.aws.amazon.com
aws 통합요청 velocity "PartitionKey" - Google 검색
2019. 10. 16. · 자동화로 얻을 수 있는 것 • Speed , Quality , Cost • 직원들이 가치를 ... AWS Lambda Amazon DynamoDB 콘텐츠 생성 콘텐츠 요청 AWS CDK App ...
www.google.com
특히 위 3번째 자료가 매우 용이하다.
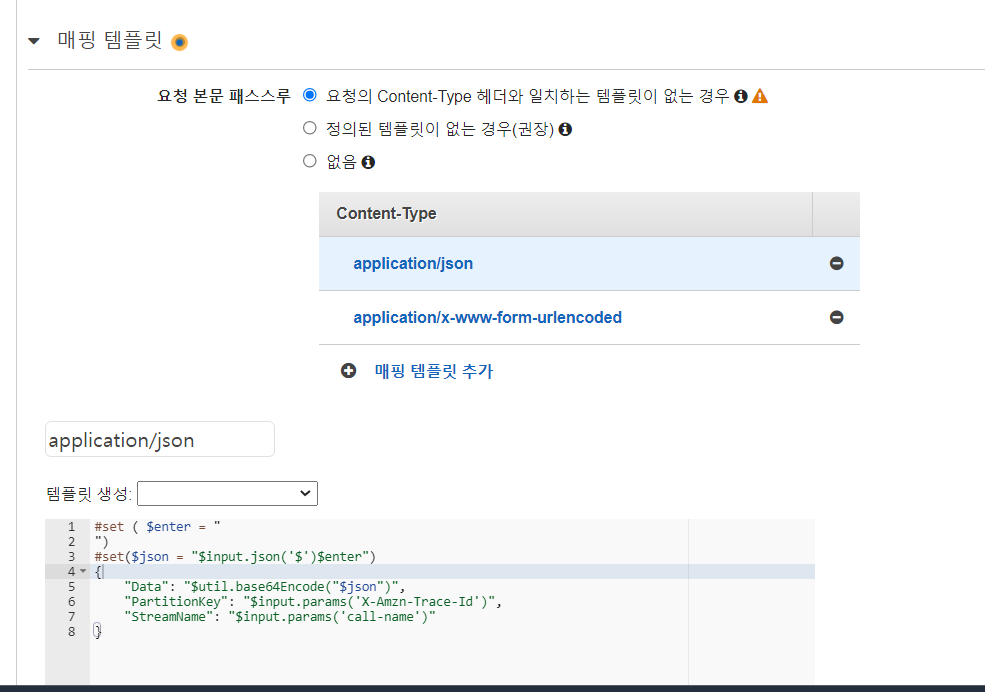
#set ( $enter = "
")
#set($json = "$input.json('$')$enter")
{
"Data": "$util.base64Encode("$json")",
"PartitionKey": "$input.params('X-Amzn-Trace-Id')",
"StreamName": "class-stream"
}

#set ( $d = '"')
#set ( $enter = "
")
#set($jsonInnerStr = "")
#foreach( $token in $input.path('$').split('&') )
#set( $keyVal = $token.split('=') )
#set( $keyValSize = $keyVal.size() )
#if( $keyValSize >= 1 )
#set( $key = $util.urlDecode($util.urlDecode($keyVal[0]) ))
#if( $keyValSize >= 2 )
#set( $val = $util.urlDecode($util.urlDecode($keyVal[1])) )
#else
#set( $val = '' )
#end
#set($jsonInnerStr = "${jsonInnerStr}${d}${key}${d} : ${d}${val}${d}")
#if($foreach.hasNext) #set($jsonInnerStr = "$jsonInnerStr,")#end
#end
#end
#set($json = "{$jsonInnerStr}$enter")
{
"Data": "$util.base64Encode("$json")",
"PartitionKey": "$input.params('X-Amzn-Trace-Id')",
"StreamName": "$input.params('stream-name')"
}
1-10) 모든 설정을 완료했으므로 배포를 한다.

1-11) 배포를 하게되면 다음 URL 엔드포인트가 생성된다. 그리고 현 부분에서 CloudWatch에 대한 로그확인 설정이 가능한데 모든 로그를 확인하게 설정하면 비용이 적지않으니 에러에 대한 부분만 보이도록 하는것이 유리하게 판단된다. URL엔드포인트 주소는 각 회사 주소에 맞게 사용자 지정 도메인으로 변경 가능하다.

2) Kinesis(Data Stream, Firehose)
2-1) Data Stream을 생성해준다 온디맨드와 프로비저닝의 설명이 자세히 있어서 생략하고 프로비저닝의 샤드는 위 글의 초기에 설명하였다.

2-2) 다음으로 Firehose를 설정하기위해 소비자 단락의 전송 스트림으로 이동한다.

2-3) Firehose는 DataStream 에서 목적지위치인 S3를 설정하면된다. 설정부분에 들어온 데이터를 람다로 처리하거나 변환하는 과정이 있는데 이는 이미 처리과정을 거쳤기에 생략하고 Firehose에서 S3에 접근할 권한 설정은 default로 생기게 하겠다. 그리고 태그부분이 중요한데 최종 비용관리 측면에서 어떤 태그에 비용이 발생하는지 측정하기 위해 매우 중요하므로 설정하는것이 중요하다.


3) S3 및 전송테스트
3-1) 어려울것없이 S3에서 bucket을 하나 만든다.

3-2) 테스트는 현재 상황상 Client 에서 데이터를 보낼 web이나 app이 없으므로 crul 명령어로 대신하여 데이터를 보낸다. 엔드포인트는 1-11에서의 URL이다. velocity에서 두가지 Content-Type 방식을 처리 해줬기에 두 데이터 형식 모두 정상적으로 보내졌다.

3-3) s3에 데이터가 잘 들어간 것을 확인할 수 있다. 다운로드해서 확인해보면 다음과 같다.


api-gateway를 사용하면 간편하게 restapi를 설계할 수 있고 데이터 적재가 원활히 이루어진다. 더불어 위 시스템을 통해 외부 appsflyer와 같이 앱에 대한 마케팅 서비스 관리측면과 연동하여 활용하는 것도 매우 용이하다 판단된다.
https://support.appsflyer.com/hc/en-us/articles/207034356-Push-API-streaming-raw-data
끝으로 위 과정에서 Kinesis의 분석애플리케이션에 새로 생긴 Studio 부분이 있는데 이 부분은 머지않아 기회가 생길 때 flink를 사용하는 processing을 해볼 것이다.
